大阪大学 社会経済研究所
Institute of Social and Economic Research
日本語での研究紹介
ChatGPTでフェイクニュースを見破る:生成AIへの信頼度に関する比較実験
原題: DO PEOPLE RELY ON ChatGPT MORE THAN THEIR PEERS TO DETECT FAKE NEWS?
著者: 付 玉皓, 花木伸行
ISER Discussion Paper No.1233
近年、ChatGPTをはじめとする生成AIが流行している。様々な生成AIツールが登場し、新たなAIブームが起こっている。生成AIは一般の人々にとって便利で、専門知識なしで使えるため、多くの人が利用できる。しかし、生成AI技術の発展に伴い、誤情報の拡散リスクも大きな懸念事項になっている。この研究では、特にフェイクニュースを見破るタスクのもとで、人々が他の人の判断よりも生成AIの判断により信頼をおくかどうかをラボ実験で検証している。
実験では、合わせて30ラウンドのフェイクニュースを見破るタスクが設定される。各ラウンドで、参加者は指定されたニュースの信憑性を二回推測し、スライドを用いて0から100までの整数で推測結果を報告する。一回目の推測の後、参加者の半分はランダムに選ばれた他の参加者の一回目の推測を参考情報として受け取り、残りの半分の参加者はChatGPTによる24回の推測からランダムに選ばれた一つを参考情報として受け取る。その後、再び推測結果を報告する。異なる情報源(他の人やChatGPT)からの参考情報に基づく推測の変化は、参加者がその情報源をどの程度信頼しているかを示す指標として解釈される。
本研究は関連する研究でよく使っている参考情報の重み(Weight of Advice)を用いて、信頼度を定量化する。その結果、参加者は他人よりもChatGPTに対して高い信頼度を示すことが明らかになった。この信頼度は、参考情報の質(正確さ)と参加者の事前信念(実験前に生成AIと人間のどちらが優れているかに関する信念)に大きく影響されることが判明した。さらに、実験で使用されたニュースは、人が書いた実際のニュースとアルゴリズムによって生成されたフェイクニュースの組み合わせであるが、ニュースの真実性がそれぞれの参考情報への信頼度に有意な影響を与えないことも確認された。
さらに、Heckman (1974,1978,1979)のサンプル選択モデルを用いて、上述の信頼度を、参考情報を利用するかどうか、利用するとしたどの程度利用するのかの2段階の意思決定に分解した結果、参考情報の情報源と事前信念との一致性がこれら2つの段階にそれぞれ影響を及ぼす一方で、参考情報の質は後者に対してのみ影響を与えることが明らかになった。
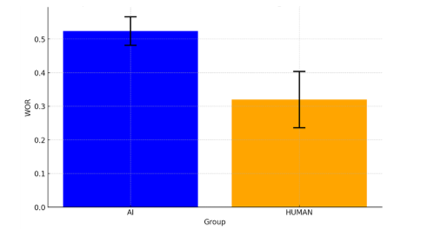
図:平均信頼度の比較
注: ChatGPTの推測を参考にしたグループ。オレンジ:他の人の推測を参考にしたグループ